Dependency Parser

Dependency Parser
DEPENDENCY PARSER FOR MALAYALAM
A Dependency parser is important for applications like sentence structure identification, machine translation, clause boundary identification,question answering system etc. No work has been done so far in the field of dependency parser for Malayalam using machine learning approaches. The main concept of Dependency parser is that each linguistic units (words) are connected to each other by a direct link. Dependency grammar has the ability to deal with the languages that are morphologically rich and have relatively free order ie, Some words such as adverbs can freely be moved inside a sentence without influencing its correctness or meaning. A majority of human languages and Indian languages are included in such category. The vast majority of the parsers for morphologically rich free word order(MoR-FWO) languages, (for example,Czech, Turkish, and so on. ) have adopted the dependency grammatical framework. Malayalam is considered as the less word order language. Which means that it is not a complete free word order language since all words cant be freely moved.
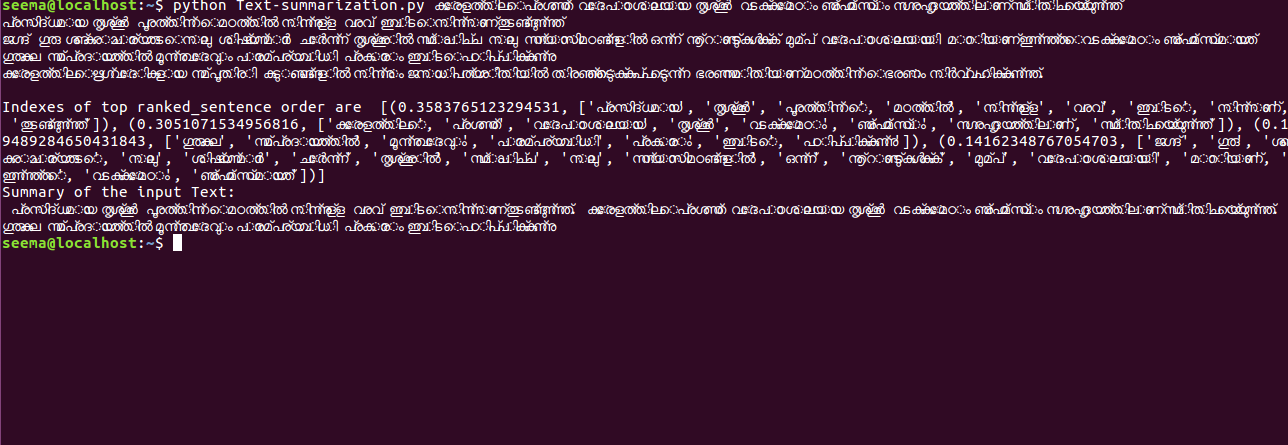
The implementation of dependency parsing involves a sequence of steps. The input sentences are first tokenized. The tokenized words are first sent to stemmer and splitted as simple words then entered in to the pos tagger to get the pos tagged data. The pos tagged sentences are then passed to the chunker to get the chunked data. Now the words contain the pos tags and the chunk tags. It is then preprocessed to the parser input format and then passed to the parser. The parsed output is then converted to a digraph format which serves as the input to the tree viewer. The tree viewer gives the parsed output to be viewed in a tree format. The main processes involved in the building of proposed system are tokenization, POS tagging, phrase tagging, format conversion, parsing, and tree generation. Transition based approach is used in our model for parsing. Focus on projective dependency parsing. The method developed for the parser uses the pos tag and chunk tag as its features for parsing the new sentences. This approach used a greedy algorithm in which a single action is chosen at every point.

Related Projects

Dwanimam – POS editor


Malayalam ChatBot

Malayalam Filthy Comment Detecor from Facebook

Malayalam Transliteration Tool
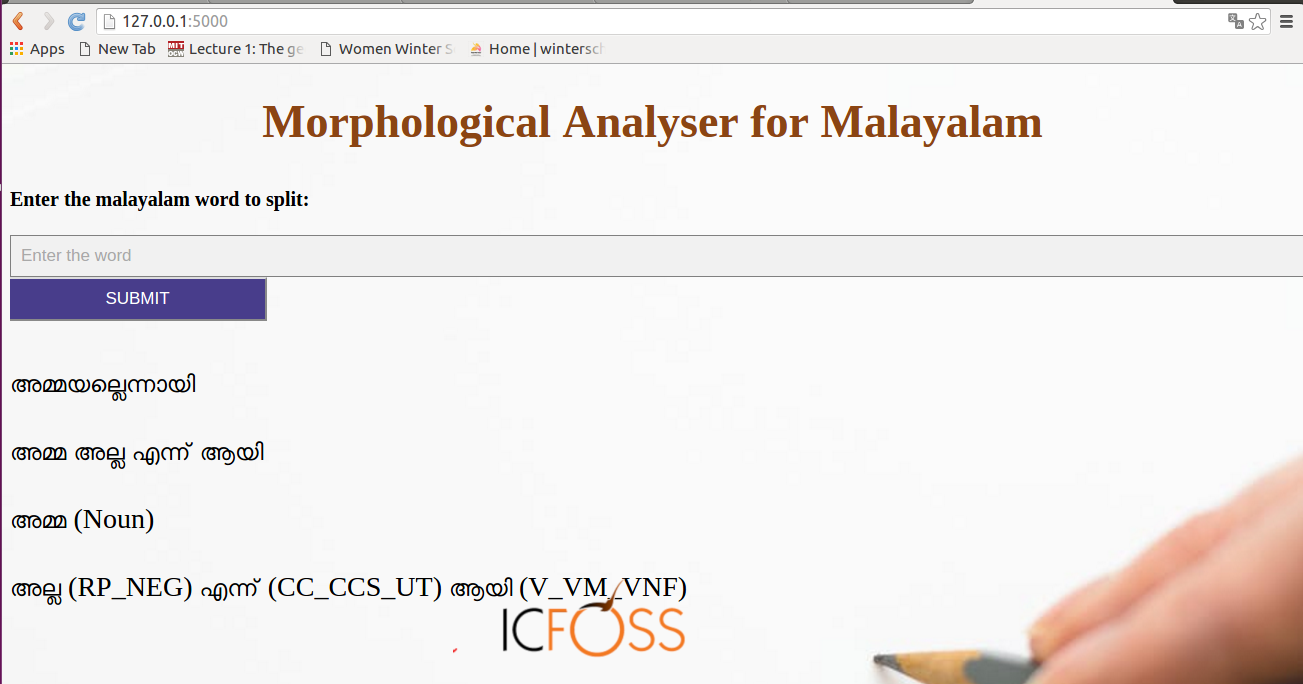
Morphological Analyzer
DHRITI – Malayalm OCR

Plagiarism Checker
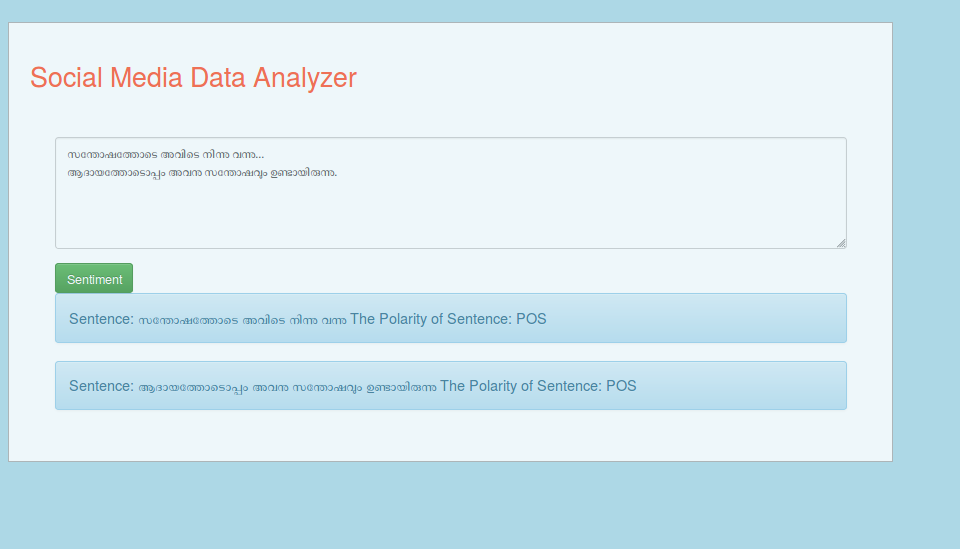
Social Media Analytics